Context is King.
In all research, no matter what technique you are using, surveys, focus groups, online communities, social data analysis, or Big Data science work, establishing context is a critical task. This task is particularly important when you aren’t in control of the way the data was collected.

With the end goal being to make a better decision, understanding context and ensuring your data is collected in a particular context is important. Decisions are not generic, they are better or worse for a specific person or organisation.
For example, if your client is a food manufacturer looking to make better innovation decisions around sustainability then they care about the impact of sustainability on food, not so much on the impact of sustainability on cars, or skincare products.
Setting the right context is easy in a survey or other primary research techniques where you ask a person a direct question because you can frame the question. For example, if you want to understand how a small set of (hopefully) representative consumers feel about sustainability within the food industry, specifically within snacking, you can send out a survey and ask them a question like:
‘thinking about the food industry, and in particular the snacks that you eat, please write in your own words what sustainability means to you’.
A revolution for research methodology
Of course surveys have their own severe limitations; small sample size, prompted bias and the small number of attributes you can ask about. Research methodology is undergoing a revolution right now powered by the vast amount of publicly available online data and new Machine Learning and Data Science techniques. But these new techniques use data that already exists, meaning you don’t have the opportunity to frame a direct question.
So how do you understand context when you can’t ask a direct question? How can you ensure the end decision you make is based on the right data?
Here are Black Swan Data, we don’t ask direct questions of consumers. Instead we look at the millions of documents they are already posting online, without bias or prompting, and we use our Data Science techniques and methodology to set those documents in a relevant context for decision making. In this post, I’ll discuss the types of context that we provide and the challenges involved in teaching computers how to understand context.
Different contexts
Establishing the context when you can’t ask a direct question is a hard task, but a fundamental one if you are to make better decisions with any data that you use. We help our clients make better decisions that are relevant for their context.
Context is King, and it can be an elusive target. Any word or topic is not relevant or irrelevant by itself. On its own it has no meaning. Take the word
‘sick’. You might think it always has the same meaning of feeling or being ill, yet it can also be an expression of annoyance
‘I’m sick of you’, or it can be the complete opposite and mean excellent or great
‘That move was sick’.
All words need to be placed into a context in order for us to understand their true meaning and whether it is relevant or not. Our brains work in relative terms, and it uses context to help decide both what something means and if it matters. The same word with the same spelling can have different meanings in different contexts.
There are many different types of context and not all contexts are important or relevant for the use cases Black Swan Data's products help solve. One of our key competitive differences vs other suppliers is we provide both
better context and
more context than anyone else.
The challenge of scale
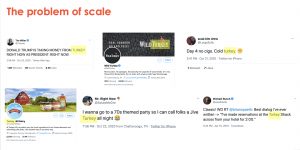
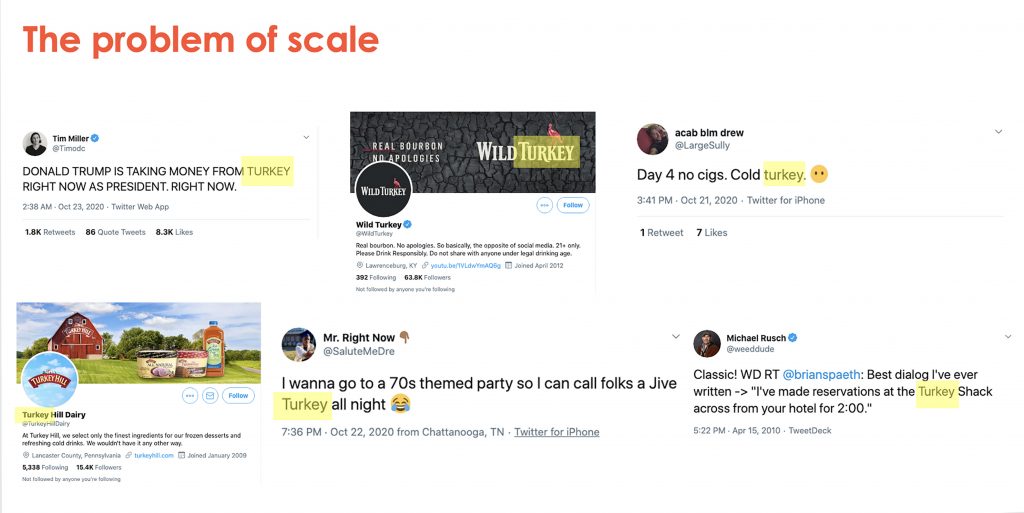
The core challenge we have is one of scale. As humans, we can easily determine what the appropriate context of each of the above tweets is. We aren’t confused in thinking that Turkey Hill Dairy is selling meat, or that Donald Trump is taking money from birds. However, we can’t get humans to read 26 million tweets in order to tell us which ones fit the context we are looking for and which ones don’t.
For that task we have to turn to computers, and for computers understanding context is hard.
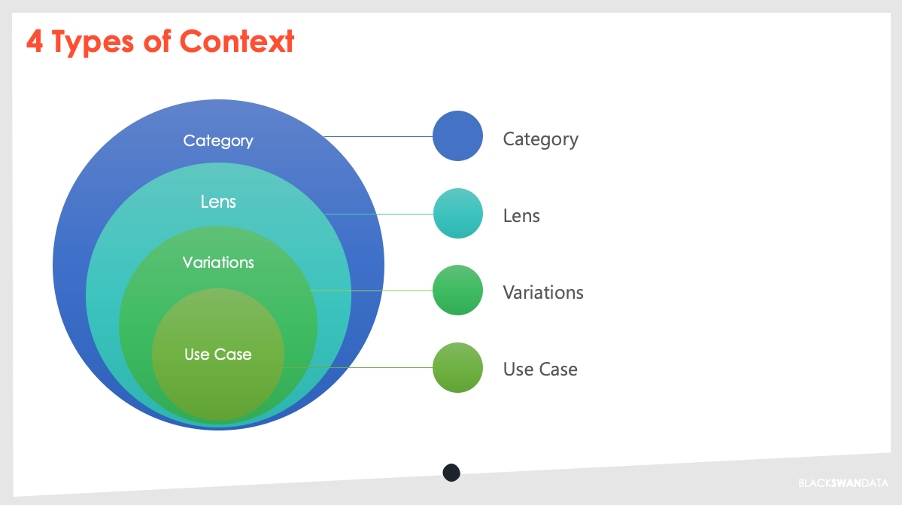
The 4 types of context
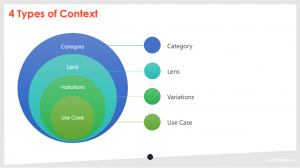
There are 4 types of context that we are trying to help computers understand, and you can think of them in layers of importance. Any one piece of text that we would try and categorise needs to pass all 4 levels of context in order to be counted as relevant and each one comes with its own challenges.
Type 1: Category Relevance

The first and most important context layer is Category relevance. In this layer we are trying to accomplish 2 main tasks:
- Is this post talking about the trend we think it is?
- Is this post talking about the trend we are looking for in the context of the category we have defined?
This first task is also known as “Disambiguation”, and it is one of the hardest problems in Natural Language Processing, the field of Data Science that Black Swan Data focuses on.
In this problem, the same word with the exact same spelling can have different meanings in different contexts. Above you can see the example again of two tweets which both mention the word ‘turkey’; one meaning the Country, and one meaning the Food. The question is then - how do you help the computer learn the many contexts this word (and all other ambiguous words) can appear in, in order to help it select the right one and disregard the rest?
This first task of Disambiguation is helped by the second task, which is establishing a category definition. Defining a category can help with Disambiguation, because it provides a reference context in which you can help judge which version of the word is the one we are looking for. For instance, if we had defined our category as Meals, then we could see there are other words in the second post that are related to meals; pepper, tomato, spinach, making it more likely that the post is about turkey the food. Whereas the first post mentions Donald Trump and President, and no food related terms, so it is less likely to be about turkey as a food.
Even then this remains a difficult task as this last tweet on the right shows. This tweet might look like it could belong to the Meals dataset as it mentions the word ‘pasta’, or the Non-Alcoholic Beverages dataset as it mentions ‘Bone Apple Tea’. However, in both cases these are jokes using the phonetic meaning of the words rather than the spelt meaning of the words, as bone apple tea is a play on the French saying “Bon Appetit”.
The important thing to understand is that this category relevance layer is the most important of the 4. If this one isn’t correct, none of the other layers will work either.
Type 2: Lenses

The next type of context relates to our Lenses. At Black Swan Data we group similar trends into what we call Lenses. These are topics like Brands, Product Types, Ingredients, Themes, etc. The task of establishing Lens context is similar to the previous one in that it also has an element of disambiguation. For example, in the Laundry and Home Cleaning dataset, Clean Green is both a brand of cleaning products and a Theme “Green Cleaning”.
There are often times, particularly with the Brand Lens, where the Brand names are ambiguous and so we need to find a way to pick apart whether the post is referring to the Brand, Product Type, or a Benefit / Theme.
In addition, we have a second context challenge when it comes to Products and Ingredients. In the image above, the meaning of the word apple is not ambiguous - apple in a food context means apple the fruit (not Apple the company, for example), but we have the additional challenge of trying to understand if someone is discussing eating an apple as a Product Type, or if they are talking about using apple as an Ingredient.
Understanding this context is important when organisations are trying to improve current and new products by adding or removing ingredients. Identifying when something is being used as an ingredient vs as a product on its own helps us improve the recommendations we can give to our clients.
Type 3: Regional Variants

The third type of context is ensuring we have all of the variants of the same topic or concept captured. For example, the regional name such as Zucchini, as it’s commonly known in the US and Italy, is the same vegetable as Courgette which is how it’s named commonly in the UK and France.
We want to try and group these terms within a context to ensure we are capturing all of the conversation that relates to that topic; including misspellings, slang terms, synonyms, and colloquial terms. This is to ensure when we are then using that volume and showing trends to our clients in
Trendscope, we don’t tell them to prioritise Courgette over Zucchini when they are the same thing.
Type 4: Use Case

The last type of context is Use Case context. By the time we get to this level we should be confident that the document we are examining, whether that is a tweet, Reddit post, news article, or Amazon review, is about the topic we think it is, in the category context we are looking for, in the Lens context we think it should be, and we have all of the variants of that topic so we are sure to capture all of the conversation.
The Use Case context varies by the type of product Black Swan is providing. Most of our use cases focus on Innovation and within Innovation we try and focus on conversations related to buying or consuming / using a product rather than on Brand Experiences or Sponsorships.
In the image above we would want to count the top tweet as a point of conversation for Red Bull within the Non-Alcoholic Beverages dataset. However, the tweet below this refers to the Formula 1 racing which we would not want to count in an Innovation use case for Beverages, and so we would remove it from our dataset. If we were looking at a Brand Perception use case or Communications use case we might want to include it, as it is relevant to how consumers perceive Red Bull overall - but as a way of prioritising in an beverage innovation use case we would not want to include the racing post.
In addition, we walk a somewhat fine line when it comes to focusing on buying the product. Here we try and focus mainly on consumers talking about buying a product, rather than retailers or brands themselves promoting or pushing a product. The guardrails here are less black and white. For example we try and remove conversation that is pure promotion (e.g. 20% off, buy 1 get 1 free, etc,) but we also don’t want to completely remove posts from brands or retailers as there are messages that consumers are reading about those products and brands.
How do most vendors and clients currently apply context?
At Black Swan Data we create specific category and market datasets (e.g. UK Skincare, or US Snacking) in order to ensure the right context is applied. Most of our competitors in the space of using Social Data for research do not create this context for their clients and instead give them an open access tool where the client / user has to write their own queries. In addition, the primary tool that user has to help establish context is a Boolean Search Query. Boolean queries are a rather blunt tool, very prone to both analyst errors and also limited in its ability to pull and clean relevant data.
Some common examples of errors include:
- Not accounting for multiple spellings
- Queries that are too broad
- Not excluding words
- Errors in syntax
- Queries that are too narrow
Let’s say we have a company that sells hair loss products. Often analysts at a company will use a tool like Brandwatch or Sprinklr to build a query that looks for mentions of the brand name (let's say Alerana) that occur within 1 word distance of the following words; hair, hair loss, cure, shampoo, spray, or mask. However, this query is not correct, as it will miss relevant brand mentions. It will capture examples such as “Alerana spray review” or “bought Alerana shampoo yesterday,” but it would miss posts like “Love Alerana, it saved me from hair loss.”
In addition, even if the tools allows users to see all of the raw documents that are pulled in from their queries (and many do not allow the user to see all of the posts), it is still too big a task to review all of the thousands or millions of documents that get pulled in to see if they are relevant or not. So users just have to hope it is right, yet often it is not, and false conclusions are drawn.
At Black Swan Data we don’t require users to write queries in order to find trends, we find the trends for them, allowing users to focus on what to do with the insight they find, rather than trying to find the insight in the first place. When it comes to relevancy and context we apply techniques that are much more powerful and comprehensive than a simple Boolean search.
Here are a few key questions to ask yourself and your vendors to ensure you are making the best decisions you can from the data you get back from any research you conduct:
- What was the context this information was set in?
- What processes or techniques do you put in place to ensure the right context?
- What is the impact to your organisation of making a decision without the right context?
To find out more about how we apply Social Prediction to drive business growth and deliver stronger innovation pipelines please
contact our team today.