Black Swan's Data Science Lead Architect Henrietta Eyre on the complexities of Sentiment Analysis, and how to build a sentiment classifier.Everyone in social media analytics is interested in sentiment analysis. Sentiment analysis refers to the area of Natural Language Processing, where the polarity of a text document is automatically determined. In a sentiment classifier, the algorithm takes the document as an input, and as an output provides a sentiment rating as either positive, negative or neutral.
Accurate sentiment rankings are incredibly useful for analysing your social media content. It takes you beyond the realms of searching for keywords that human intuition tells you may indicate sentiment, and allows you to tag all text with a sentiment rating – regardless of whether you’ve seen the likes of its content before.
So how can we build a sentiment classifier?
A widely used algorithm is the
Naïve Bayes Classifier. It has a theoretical backbone of Bayes’ Theorem (recently covered in
Jude Bowyer’s blog post). If we pass a set of numbers to the algorithm then it will look for the boundary within a vector space for the different sentiment classes, and will label our input accordingly. Now we have a text input, and so the numerical input is determined by counting up the frequency of the words in the input text.
So
“We love Black Swan and we love data science” would be turned into the following form:
{“we”: 2, “love”:2, “black”: 1, “swan”:1, “and”:1, “data”:1, “science”:1 }
And the numbers would be used to calculate our sentiment label.
This method is proven to work really well for lots of text forms. When we have longer text expressing a given sentiment, the word counts which the algorithm has learned to associate more strongly with a positive or negative sentiment allow it to give unseen text a sentiment label with good accuracy. However, in the space of social media this model doesn’t work so well.
Take Twitter as an example. 140 characters is not very much space for our algorithms to work with, and the Naïve Bayes algorithm would struggle to find an accurate sentiment class for each message.
Instead, we have to look a bit deeper into the way that people engage with social media, and pick apart the way in which they use language differently. Here are some of the insights we found within Twitter data:

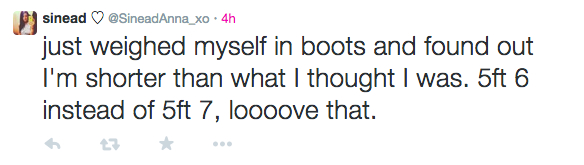
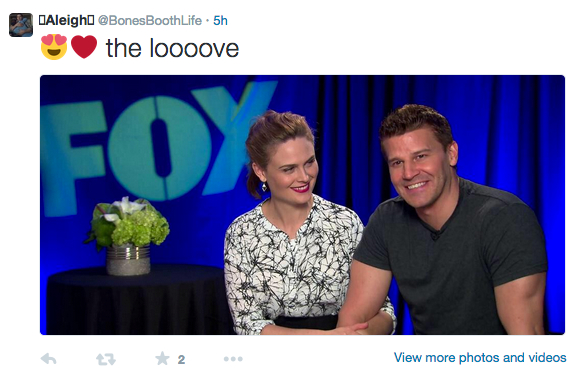
We found that users elongate their words in order to emphasise their sentiment. So whereas ‘I love the sky’ would indicate a positive sentiment, the user elongating ‘love’ to ‘loooove’ shows a heightened positive sentiment.
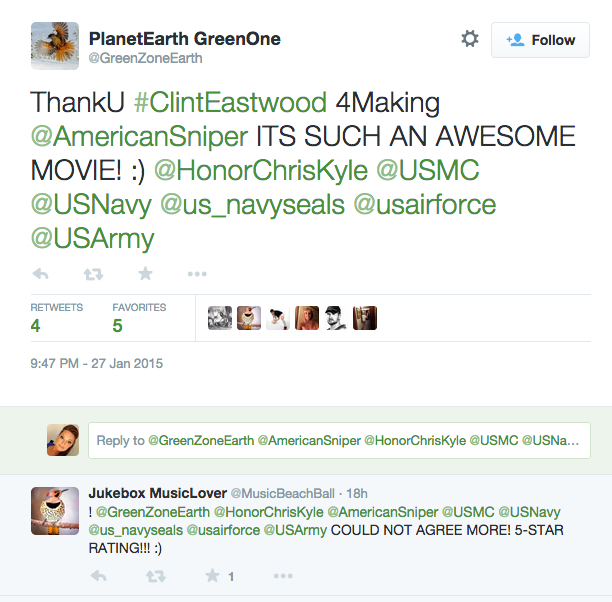
We also found that users overly punctuate to accentuate their message’s sentiment. In the above example, the user has used three exclamation marks. This can be paired with ‘5-STAR RATING’ which is expressing a positive sentiment, to indicate a heightened positive sentiment.
Emoticons are extremely important in representing sentiment too. But we can’t simply map a happy emoticon to a positive sentiment and an unhappy emoticon to a negative sentiment. Sometimes emoticons when paired with an opposing sentiment in the text can indicate sarcasm.
We can also find opposing sentiments in the same message:
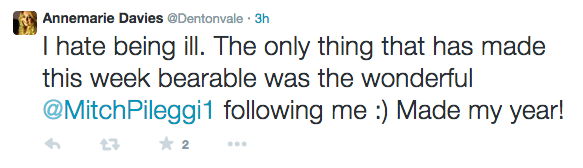
Here the user is expressing negative sentiment towards being ill, but positive sentiment to a new user following them. How do we deal with assigning a sentiment tag to the whole message?
These are all factors which need to be taken into account when building a sentiment algorithm. The golden rule is that there is no ‘one size fits’ all algorithm to handle sentiment. Every data channel requires its own model, and your models will need to evolve as social media habits evolve.
Perhaps this is why sentiment is a problem we love to work on. We do love a challenge at Black Swan Data!