Our unique trend prediction tool Trendscope ingests millions of Social data conversations from sources all over the world. And our datasets are constantly growing.
One of the most exciting aspects of our data science approach is that we not only observe how trends manifest themselves across different
categories, but across different
countriestoo.
Whenever we launch a new country dataset on Trendscope, our dataset build team must localise the content to the country and target language. As well as localising Product and Brand lists, we also need to make sure our AI and NLP techniques are effective for each language.
This year our Dataset team has been busy building new datasets in Turkish and Russian. As morphologically complex languages, both presented some interesting challenges. Language morphology needed to be our main area of focus.
The Russian challenge
Russian is an East Slavic language, written in Cyrillic rather than the Latin alphabet. This meant that all our taxonomies on Trendscope – including many global brand names – needed to be translated into Cyrillic. For example, you’ll often see Pepsi written as Пепси in Russia.
Like most Slavic languages, Russian also has a case system. Nouns can appear in many different forms, depending on which of the six cases is being used (nominative, genitive, accusative, etc.). Plus there’s also the influence of plurals and noun gender. Often we’d find as many as 12 different variations for each word.
Take Liquorice as an example. It was the top trending ingredient for Non-Alcoholic Beverages in January (it has medicinal and weight loss properties, so is often added to tea).
We started with English with regional variations: liquourice | licorice
These were then translated into Russian: лакрица | солодка
Then these were expanded using our morphological generator: лакрица | лакрице | лакрицей | лакрицу | лакрицы | лакриц | лакрицам | лакрицами | лакрицах | солодка | солодке | солодки | солодкой | солодку | солодок | солодкам | солодками | солодках
Translating in Turkish
Turkish is a Turkic language written in Latin. In the Latin alphabet some letters are modified to account for specific phonetic requirements. Turkish is also an agglutinative language, where complex words are formed by stringing together small language units without changing their spelling or phonetics. Essentially, this meant that we’d find one word appearing in lots of variations – often 20 or more. It was important that these variations were captured accurately to cover the conversations in this market.
The Black Swan Data approach
Our Data Science team applied morphological expansion to all the sub-lenses in our Ingredients and Products lenses. This is an NLP expansion technique that examines our seed inclusion lists and expands them by the morphological rules of Turkish or Russian.
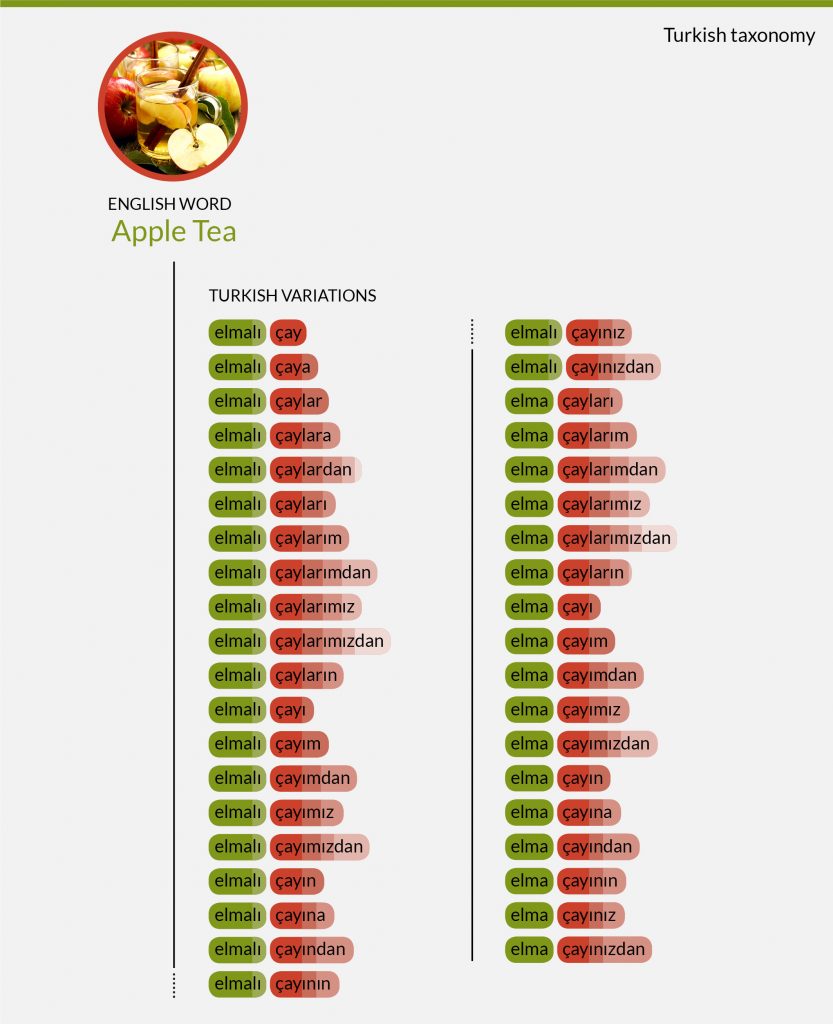
Using this method we captured all of the different word variations based on case, gender, singular/plural context and tense. For Turkish we were also able to repeat this technique with great results across Benefits and Themes lenses too.
All of these sub-lenses were then checked and refined by native speakers to make sure the quality of our output was accurate.
Are you getting the whole conversation?
You may be using Social listening tools to track conversations online in multiple countries. But are you accounting for the many variants of word types in each language? If not, it’s likely you’re missing a large part of the conversation.
Not only that, but more and more we’re seeing trends moving across cultures and countries. By understanding the trends emerging in one country, you can take advantage of a longer lead time to understand the potential trends in your target market.