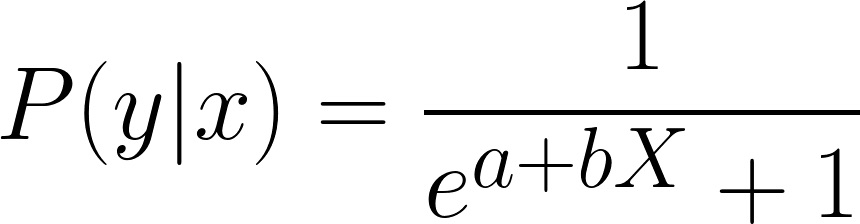Can we predict our identity from the way we use language?
We love social media at Black Swan, and what particularly interests us is analysing the language used across these different media platforms, as well as observing the common and differing features between different social demographics. Applying this to social data from a platform such as Twitter would allow us to unlock the secrets of the social media sphere and study different aspects of a person’s identity such as age or gender, simply from their 140 character social media message.
But can it really be done? The short answer is yes, but in truth the problem is really quite complex. For the most part this is due to how language is passed on, and how it develops as we age, as well as the fact that everyone is shaped differently. This is because of several social variables such as individual experience, personality or cultural influence. In addition, many speakers often adapt their language to their audience which means people can choose to show their identity more or less explicitly in their language, depending on the situation.
In this way, Twitter is interesting. It takes multiple audiences of varying backgrounds and ages and represents them all in the same 140 character messages. Tweets can be targeted to a person, a group, or to the general public and people might be more formal due to the reach of their tweets, or the character limitation might force them to be informal. Also, it has been found that differences in language use for age categories hardly change as one gets older and overall this makes it difficult to detect and define features of users from the language used in these tweets.
So, it turns out a person’s social identity is actually quite complicated, we are all moulded in many different ways and this corresponds to the way people interact. It means making predictions solely based on a Tweet, especially due to its limited length, can be incredibly tough. One needs a clever combination of algorithms and data to predict accurately. Nevertheless it can be done, as shown below:
Let's get started:
Predicting Gender
Selecting our features:
Here we have an example of a female tweeter who happens to be an avid One Direction fan.

Tweets have been found to possess more of the following for females than males.
- Use more self references such as 'I'
- Use emoticons <3,: D, ;)
- Ellipses …….
- Character repetition' gawwwwwwd' ,
- Repeated exclamation marks !!!
- Puzzled punctuation '???!'
- 'OMG'
Further features we select for tweets may be:
- Capitalisation
- #Hashtags
- Mentions
- Punctuation
- Words in the message
These features, represented as a vector X will become input features into our algorithm.
Selecting our algorithm:
A widely used technique for classification is Logistic Regression. It will fit a linear model to the data and then convert a real number into a classification. In the case of classification with two classes, in our example this is Male or Female, the model estimates a conditional distribution :
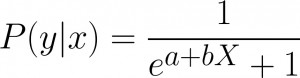
Where b''s are the parameters to estimate and these will assign weights to the features X. This is also known as the Logistic function.
Once we have counted the frequencies of the features that have appeared in our female tweet example and applied them to the linear equation, it will return a real number. Given the features we observe in the tweets, we can train all these real numbers, such that when we apply them to our logistic function it will output the probability of 1, we are 100% we are that the tweet example belongs to class 'Female', or 0 being 0% sure .
With our fully trained algorithm we can proceed to classify the millions of tweets that are out there and hope it provides an accurate prediction of the many characteristics of the Tweeter.